
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2023-10-13 来源:黑马程序员 浏览量:

通用网络爬虫的采集目标是整个互联网上的所有网页,它会先从一个或多个初始URL开始,获取初始URL对应的网页数据,并不断从该网页数据中抽取新的URL放到队列中,直至满足一定的条件后停止。
通用网络爬虫的工作原理如图1所示。
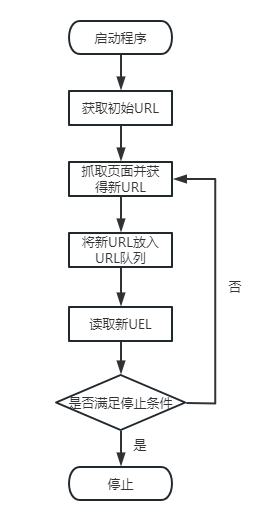
通用网络爬虫的工作原理
关于图1中各环节的介绍如下。
(1)获取初始URL。初始URL是精心挑选的一个或多个URL,也称种子URL,它既可以由用户指定,也可以由待采集的初始网页指定。
(2)有了初始URL之后,需要根据初始URL抓取对应的网页,之后将该网页存储到原始网页数据库中,并且在抓取网页的同时对网页内容进行解析,从中提取出新URL。
(3)有了新URL之后,需要将新URL放入URL队列中。
(4)从URL队列中读取新URL,以准备根据URL抓取下一个网页。
(5)若网络爬虫满足设置的停止条件,则停止采集;若网络爬虫没有满足设置的停止条件,则继续根据新URL抓取对应的网页,并重复步骤(2)~步骤(5)。需要注意的是,如果没有设置停止条件,网络爬虫会一直采集下去,直到没有可以采集的新URL为止。




















.jpg)